Table of Contents
Home
Welcome on my WikiBlog! You can find a mixed collection of German and English content here. This website is always work in progress as there is a lot to do and so little time.
Willkommen auf meinem WikiBlog! Hier gibt es eine Mischung aus deutschen und englischen Inhalten. Meistens habe ich zu viele Ideen und zu wenig Zeit und so ist auch diese Website eine ständige Baustelle.
FuCamp: Laptops in Vorlesungen - Fluch oder Segen?
In Furtwangen wurde Kritik an den Notebooks in Vorlesungen von Seiten der Professoren geäußert. Anwesend auch ein Professor der Hochschule.
Folgend der Mitschrieb einiger Aussagen/Lösungsideen, …
Notebooks können gut genutzt werden für Protokolle, Recherche, … Studierende finden es unverschämt, dass ihnen während der Vorlesung der Kontakt nach außen verboten wird vs. der Professor, der versucht, etwas mitzuteilen und die Studierenden lenken sich ab.
Heute existiert eine andere Kommunikationskultur als früher - wie unterscheiden sie sich? Müsste man Laptop-Nutzung verbieten oder wie bekommt man sie sonst in den Griff? In Dänemark wurden Laptops teilweise sehr integriert, dass Ablenkungen von Studierendenseite selbst als störend empfunden wurde. Zum Beispiel durch Skripte ergänzen oder Studierende müssen während der Vorlesung ein Programm erstellen.
Digitale Mitschriebe bieten große Vorteile (können z.B. an nicht anwesende Studierende weitergegeben werden). Langweilige/schlechte Vorlesung - gehen vs. ablenken und trotzdem noch ein wenig aufpassen.
In manchen Vorlesungen ist es offensichtlich, dass Laptops nicht zu studienzwecken einzusetzen. Teilweise gibt es auch Pflichtveranstaltungen, wo man hingehen muss. Außerdem sind Studierende teilweise gestresst/haben nicht so viel Zeit und erledigen andere kleine Aufgaben wie E-Mails schreiben.
Professoren empfinden es als sehr wichtig, dass sie die ungeteilte Aufmerksamkeit bekommen und ihre Selektionsfunktion ausüben können, da sie eine Fachsicht haben und die Studierenden selbst nicht unbedingt beurteilen können, ob die Inhalte interessant sind.
Problem bei Pflichtvorlesungen, dass Studierende da sind, die ohne Anwesenheitspflicht nicht da wären.
Es gibt Vorlesungen, in denen Laptops nicht sinnvoll und es gibt andere, in denen man mit dem Laptop z.B. Aufgaben zum aktuell behandelten Stoff lösen kann.
Laptops in Vorlesungen lenken auch andere Studierende, insbesondere die, die dahinter sitzen, teilweise auch akustische Störung.
In manchen Vorlesungen sind Laptops zur Recherche sehr sinnvoll.
Sensibilisierung für das Thema wird eher als Lösung gesehen als ein generelles Verbot, da damit auch sinnvolle Einsatzgebiete verboten werden. Es ist auch eine Frage der Grundeinstellung. Idee einer Selbstverpflichtung - aber es gibt evtl. immer schwarze Schafe. Soziale Bindung/Kontrolle ist in Kleingruppen möglich.
Durch handschriftliche Mitschriebe wird man gezwungen, die Vorlesung wirklich nachzuarbeiten. Am Computer dagegen kann man dagegen übersichtlicher Mitschreiben und auch die mitgeschriebenen Inhalte durchsuchen.
Problem ist, dass die Diskussion eigentlich alle erreichen müsste, und nicht nur diejenigen, die sowieso für das Thema sensibilisiert sind.
Lösungsvorschläge:
- Wir hoffen, dass sich die Leute ändern
- “Holzhammer-Methode” - Professoren sagen es am Anfang der Vorlesung
- Graswurzelbewegung - aus der Menge heraus wird Druck aufgebaut
Bericht auch, dass Ermahnen anderer nicht unbedingt hilft.
Eventuell sollte es auch einen Grundsatz/ein Leitbild geben. Aufruf an die Studierenden, hierfür Vorschläge einzureichen.
FuCamp: Blinde am PC
Session mit Markus Heurung, @muhh, markusheurung.de, Lehrer am Berufsförderungswerk Würzberg (bieten Umschulungen an), bildet in IT-Berufen auf, in diesem Fall für blinde und sehbehinderte Menschen zur Wiedereingliederung. Blindenschrift lernen, leben als Blinder.
Hilfsmittel Nr. 1 sind Screenreader, der den Bildschirminhalt ausliest und für Blinde zugänglich macht. Die Darstellung kann über eine Braille-Zeile oder Sprachausgabe erfolgen. Der Screenreader bekommt seine Informationen von einfachen Programmierschnittstellen bis hin zur Grafikkarte, wo die Cursorposition erfragt wird. Einer der verbreitetsten ist Jaws, auch verbreitet Virgo/Cobra, Window Eyes und die OpenSource Software NVDA. Von allen gibt es Demo-Versionen, die meist auf 40 Minuten pro Boot… Ubuntu kann man auch blind installieren, bei Windows geht das nicht, bei Mac OS ist auch einiges vorhanden.
In den USA benutzen die meisten einen Screenreader mit Sprachausgabe aus Kostengründen, in Deutschland sind eher die Braillezeilen gefragt. Viele arbeiten auch kombiniert mit beidem.
Screenreader sind extrem konfigurierbar, Sprachgeschwindigkeit einstellbar, “Bubbles” aus der Statuszeile werden vorgelesen. Es gibt unterschiedliche Stimmen, auch unterschiedliche Stimmen für verschiedene Funktionen.
Das Wichtigste für Blinde bei Programmen und auch Websites sind Shortcuts, Grafiksymbole beschriften (z.B. alt-Attribute bei Bildern auf Websites). Es muss des Weiteren alles mit der Tastatur erreichbar sein. Bei Websites können Screenreader z.B. auch Übersichten mit allen Überschriften oder Links anzeigen.
FuCamp: La Blogosphère en France
Session mit Dr. Heiner Wittmann von der Ernst Klett AG, ist dort verantwortlich für Web 2.0 bei Klett.
In Frankreich vs. Deutschland 9 vs. 1 Millionen Blogs, in Frankreich viel mehr Blogs, da aktivere Blog-Platformen. Politiker bloggen teilweise selbst, teilweise lassen sie auch bloggen (auch gemischt in einem Blog). Mind. 80 verschiedene franz. Abgeordnete haben Blogs. In Deutschland gibt es das weniger, da ca. die Hälfte der Abgeordneten mit Listen gewählt werden, französische Politiker sind eher gezwungen, mit ihren Wählern im Kontakt zu bleiben. In Frankreich können einzelne Politiker direkt abgewählt werden, in Deutschland quasi nicht möglich wegen den Listen.
In Frankreich wird oft über die Arbeit an Berichte und Projekten gebloggt, eine Offenheit, die wir in Deutschland oft noch nicht haben.
Bei französischen Medien gibt es teilweise Blogs der Zuschauer, bei Le Monde sind teilweise bekannte Blogs in Frankreich gehostet.
Es gibt Theorien, dass beim Referendum zur EU-Verfassung die Blogs auch mit entschieden haben.
Die Blogs vernetzen sich oft mit anderen lokalen Blogs.
Mit Sicherheit stecken gerade bei Politikern wie Sarkozy PR-Berater dahinter, die normalen Abgeordneten machen das aber wohl doch selbst.
Mehr Infos, Links etc. auf http://romanistik.info/blogs.html
FuCamp: Freie Suche
Präsentiert von zwei Informatikstudenten (Uni Karlsruhe):
- Florian Richter
- Michael Hamann
Motivation
- Suche ist eine der wichtigsten Dinge im Web überhaupt
- Die Websuche ist momentan in der Hand weniger großes Konzerne
- Zensur, Kontrolle - wie vertrauenswürdig sind derartig riesige Privatunternehmern
YaCy
- P2P Suchmaschine - verteilte Indexierung des Webs
- 2003 Gegründet
- momentan ca. 7 aktive Entwickler
- momentan ca. 70 Aktive Teilnehmer im P2P Netz
P2P
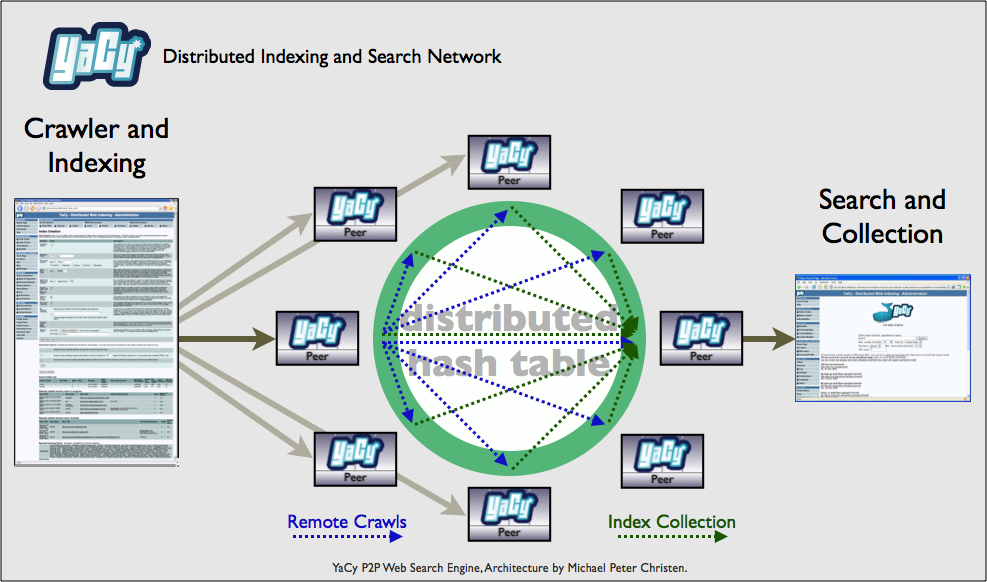
Zensur
- Jeder Peer kann Blacklists anlegen, diese können ausgetauscht werden
- Gedacht, um z.B. Werbung, Linkfarmen, etc. auszuschließen, teilweise auch eBay, Amazon etc.
- Problem: Bei Verteilung wird der Index teilweise auch auf den anderen Peers nochmal nach dortigen Blacklists zensiert
- Zensur vs. Spam/unerwünschte Inhalte?
Weitere Einsatzzwecke
- Firmen Intranets
- Themensuchmaschinen
- ScienceNet am KIT
Ersatz für Google?
- Bereits brauchbare Ergebnisse
- Index umfasst natürlich nicht alles.
- Lösung: Metasuchmaschine - Paxle?
Auch online:
FuCamp: Distributed Social Networks
Session mit Mario Volke, studiert Informatik und hat sich von der semantischen Schiene her mit Distributed Social Networks beschäftigt.
Es geht darum, keine geschlossene Plattformen zu haben ohne Kontrolle über die eigenen Daten. Die Idee ist, plattformübergreifend Freunde zu haben und vielleicht sogar die Daten selbst zu speichern. Hierzu sind offene Schnittstellen nötig.
Was gibt es?
Google OpenSocial: Wollen bestehende Netzwerke öffnen mit Hilfe von APIs für Userdaten, Freunde, Aktivitäten. Alles ist sehr unspezifisch. Nicht möglich sind aber plattformübergreifende Freundschaften, die Daten liegen nach wie vor bei den geschlossenen Plattformen, keine wirkliche Dezentralisierung.
NoseRub ist ein OpenSource-Projekt, eine Plattform, die man selbst installieren kann. NoseRub spezifiziert ein Protokoll, mit offenen Technologien mit OpenID, RSS, FOAF. Man kann Streams aggregieren, Livestreaming (wie z.B. FriendFeed). Man hat eine URL, die die eigene ID darstellt. Die Profile werden über FOAF synchronisiert.
HelloWorld - www.helloworld-network.org, aus Diplomarbeit entstanden, noch nicht live, SourCode in ein paar Monaten… Authentifizierung mit ähnlichem Protokoll wie OpenID mit Public Key Verfahren. Dezentralität: Profile, Unterprofile, freie Wahl des Speicherortes dieser Profile. Spezielles Protokoll zur Verbindung der verschiedenen HelloWorld-Server existiert. Sicherheit mit Hilfe von Verschlüsselung und Signaturen. Die Kommunikation soll über E-Mail oder Peer-to-peer (z.B. Freenet), ist aber noch nicht implementiert. Es gibt von der RE:Publica eine Aufzeichnung der dortigen Live-Demo.
Ein Projekt von Mario selbst ist origo. Eine Mischung aus Serverapplikation mit PHP mit einem Datenspeicher und einem Flex Client, über das man das Profil (FOAF) editieren kann und das Netzwerk erkunden kann. Der Server kümmert sich auch um die Publizierung der Profile. Es gibt URLs für die Profile, können auch Weiterleitungen sein. Problem ist, dass FOAF noch etwas beschränkt ist. Der Client enthält einen Browser für das soziale Netzwerk, auch nach spezifischen Beziehungen. Beziehungen wie child of/parent of werden auch erkannt. Auf http://code.google.com/p/origo/ gibt es den Code und Links zu demos. Auch externe Profile können mit angegeben werden. Alles ist noch experimentell, auch die Performance ist noch problematisch, da die Daten wirklich dezentral auf anderen Servern gespeichert sind und erst angefragt werden müssen. Es werden ausschließlich standardisierte Protokolle verwendet, Dinge wie andere Personen über neue Freundschaften informieren funktionieren noch nicht.
Was wollen wir?
Kontrolle über die eigenen, persönlichen Daten.
Frage: Wie werden die Profildaten wieder zurück in anderen Profile synchronisiert. Plattformen sollten die Daten nur aus FOAF-Profilen nur cachen, die anderen müssen diese Daten ab und zu synchronisieren. Die eigenen Profile enthalten die Daten, die einzelnen Plattformen sind nur Clients. Problem, dass die Plattformen die Caches richtig verwalten müssen/garantieren müssen, dass die Daten auch wirklich wieder gelöscht werden, wenn der Benutzer es will. Problem, dass einmal veröffentlichte Daten schlecht zurückgenommen werden kann.
Frage auch nach einem Geschäftsmodell, einem Markt, … Das Daten/Profil erstellen fällt als Geschäftsmodell eventuell weg oder wird es hier wieder zentrale Anbieter geben? Vergleich mit E-Mails, wo auch Geld mit verdient wird. Die Frage ist, ob XMPP genutzt werden könnte, für die Kommunikation. Problem auch der dezentralen Adressierung, ob E-Mail-Adressformat oder URI, …
Das Problem ist auch, dass der Ottonormaluser nicht das Problem sieht/den Mehrwert erkennt. Auch die Akzeptanz von Kryptographie ist nicht unbedingt gegeben (siehe E-Mail).
Interessante Diskussion zum Thema Zentrale Identität vs. verteilte Daten usw.. Problem dass man die eigenen Daten an eine private Firma überträgt.
Es ist klar, dass die zentralen Plattformen, die die Massen haben, kaum Interesse haben an dezentralen Netzwerken, aber sie könnten dazu gezwungen werden (siehe AOL…). Selbes Problem existiert auch bei Instant Messaging, Google stellt sich hier hinter Jabber, aber Jabber setzt sich bis jetzt immer noch nicht durch…
FuCamp - E-Learning 2.0
Session mit Katrin Mathis, sie schreibt E-Learning Bachelor Thesis - E-Learning in sozialen Netzwerken, wie kann man es vermarkten, …
Warum brauchen wir E-Learning 2.0? Wissen kurzlebig, neue Berufsbilder, hohe Qualifikation gefordert, Arbeitsbedingungen verändert, arbeiten von zu hause aus. Früher einmal gelernt, heute lebenslanges lernen.
Die NetGeneration der digital natives (1977-1997) sind mit dem Internet verbunden. Machen viele Dinge gleichzeitig, Fernsehen ist nur im Hintergrund, da sie eher aktiv. Auch kritisiert wird die kurze Aufmerksamkeitsspanne, es gibt aber auch Wissenschaftler, die das positiver bewerten, da es zu unserer modernen Kommunikation mit SMS etc. passt. Auch eine globale Generation, ähnlicher Lebensstil auf der ganzen Welt. Sie will Entscheidungsfreiheit, keine langfristige Arbeit, alles anpassen, selbst zusammenstellen, … Zusammenarbeit mit anderen z.B. über Instant Messaging spielt eine wichtige Rolle. Sie forschen nach, informieren sich z.B. über Produkte aus dem Supermarkt, dank neuer Datenlage, geben diese Informationen/Kaufentscheidungen auch weiter. Unterhaltung und innovative Arbeitgeber sind wichtig. Heute sind auch die nötigen Werkzeuge vorhanden (siehe Wahl von Obama). Man muss auch sehen, dass die Net Generation nicht die gesamte Generation umfasst. Irgendwie muss ich sagen, das Gefühl habe, dass die net generation nur einen eher kleinen Teil umfasst…
Kontakte als Wissensquellen sind heute wichtig, das wirklich wichtige heute ist Methodenwissen, eher Konzepte als das konkrete Wissen lernen. Auch die Trennung von Job und Privatleben wird aufgehoben. Im Internet gibt es keine Beschränkungen für die Spezialisierung des Wissen (z.B. exotische Sprachen). Der Lehrerende ist weniger ein Lehrer als mehr ein Coach, der z.B. filtert. Formelles vs. informelles lernen (z.B. von Kollegen, in Gesprächen, …). Auch Kinder fangen schon mit Computern, Lego, … an. Formelles lernen macht einen Großteil der Ausgaben aus, informelles lernen dagegen liefert einen Großteil des Wissens. Informelles lernen kann man z.B. durch gemütliche Ecken zum Zusammensitzen fördern, mit z.B. Flipcharts etc. ausgestattet. Diskussion, ob wir gerade formal oder informell lernen, scheint eher ein Zwischending zu sein. Wir kommen nicht mit einem bestimmten Ziel hierher, nicht, um z.B. einen Schein zu bekommen. Es gibt Unterschiede zwischen Wissensquellen lesen und lernen, lernen, ist, wenn man das wissen auch nutzen kann. Das meiste informelle Lernen passiert zufällig, aber ist Wissensmanagement lernen? Nicht jede Kommunikation ist lernen, aber man muss kommunizieren, um zu lernen. Informelles lernen ist schwer messbar, schwer kontrollierbar, kommt beim Kaffeetrinken wirklich etwas zustande.
Informelles lernen ist für Grundlagen weniger geeignet, eher für erfahrererne Lernen, hier aber durchaus effektiver.
Also Technologien gibt es Personal-Learning Environments zum selbst zusammenstellen aus Widgets, z.B. Vokabeln, Tageszeitung, …, kleine Einheiten, Stichwort Microlearning. Auch im Bereich Open Source/Content gibt es einiges. Mobile Learning gibt es bis jetzt eher wenig, wird aber zunehmend. Game-based Learning, gerade für Kinder spielerisches Lernen. VOIP Technologien, z.B. bei Sprachenlernen mit Muttersprachlern unterhalten. Software as a Service ist eine weitere Entwicklung, die Software wird im Internet angeboten.
Tools die eingesetzt werden sind Blogs, Wikis, Podcasts, File sharing, RSS, Tagging zum Filtern, Social Bookmarking ebenfalls zum Filtern von Informationen, Social Networking zur Beantwortung von Fragen. Chat und VOIP zur Kommunikation werden ebenfalls eingesetzt.
Edmodo ist eigentlich eine reine Microblogging-Seite, aber man kann auch Termine etc. verschicken. Gedacht für Grund- und Weiterführende Schule. Katrin hat eine FaceBook-Applikation apps.facebook.com/thesisapp. Mit angebundenem Learning Managements System, man kann seine Skills einschätzen, man kann Gruppen bilden, es gibt ein Diskussionsforum, Anbindung an Delicious, Twitter, RSS-Feeds, Aufgabenverwaltung. Es gibt nicht eine Plattform, sondern viele, kein klares Ziel, nur auf Anfrage, problembasiert, geht von den Benutzern selbst aus, mit Echtzeitkommunikation.
Herausforderungen sind Datenschutz, was machen die Firmen mit den Daten? Wie findet man sinnvolle Lernmaßnahmen? Es gibt keine Standards, … Wie kann man informelles Lernen formalisieren?
Zukunft? Semantic Web - intelligent agents, die Hilfestellungen leisten beim finden und filtern geeigneter Informationen, Ubiquitous computing - mobile learning, Internet überall, Virtuelle Welten/3D-Technik, einfacherere Kommunikation, …
Wie setzt man die Tools richtig ein, dies ist die eigentliche Herausforderung beim E-Learning, damit die Lernplattformen wirklich genutzt werden.
Barcamp Stuttgart: Going international
Mario Ruckh von Kindo, selbst mit Webservice in 17 Sprachen online gegangen. Kindo ist privates soziales Netzwerk, mit Geburtstagen, Fotos, Status, Microblogging usw. für Familien. Stammbäume vom Stars/berühmten Personen wurden öffentlich gemacht. Nicht um Familie kennen zu lernen, sondern für Kontakt von bestehenden Beziehungen/weiter entfernte Verwandte. Mittlerweile übernommen von myHeritage, Stammbaum der Welt. eCommerce-Empfehlungen um Geld zu verdienen z.B. bei Geburtstagen, Hochzeitstagen etc. um Geschenke zu verschicken.
Karte mit Ländergröße nach Internetnutzer, Potentiale der Zukunft sind nicht im nicht-englisch Englischen Sprachenraum, Spanisch und Chinesisch 56% der Weltbevölkerung. Insbesondere für Nischenprodukte sind größere Märkte interessant, je spezieller desto wichtiger ist Internationalisierung. Die technischen Möglichkeiten sind auch schon weit fortgeschritten, fertige Module sind vorhanden. Wenn man selber keine anderen Sprachen anbietet, können andere Services sich in anderen Sprachen etablieren - Wettbewerb.
In Europa wird viel schneller internationalisiert als in den USA weil die Märkte kleiner sind, Internationalisierung ist eine Stärke der europäischen Märkte/Unternehmen.
Herangehensweise: ausprobieren, unterschiedliche Aufnahme testen. Internationalisierung ist einfach und skaliert, deshalb kann man gut ausprobieren. Übersetzer suchen und diese machen ein wenig Werbung, in wichtigen Ländern intensiver Werbung machen.
Nur Sprache oder auch verschiedene Kulturen abbilden, also lokalisieren? Gibt es unterschiedliche Einstellungen z.B. zum Produkt, bei Familiennetzwerk unterschiedliche Verhältnisse zur Familie in unterschiedlichen Kulturen. Schwerpunktmäßig finden von lokalen Partnern oder Partnern, die selbst international sind.
Community-Based Internationalization - Crowdsourcing, bei FaceBook inline Übersetzen - Text anklicken, deutsche Übersetzung eintragen z.B.. In einem halben Jahr 30-50 Sprachen. Mehrstufiger Prozess, jeder kann Übersetzung vorschlagen, dann Bewertung durch die Community, nach Aktivität wird die Übersetzung eingefroren. Am Ende noch einmal redaktionell darüber schauen.
Neue Features eventuell immer erst in allen Sprachen fertig machen?
Plattform für Community-Übersetzungen: transifex.org - freie Software, auch hosted, programmiersprachenneutral. Übesetzerteam, wahlweise auch online, landet in Software oder Website etc.. Python und diverse Script-Sprachen um die Versionskontrollsysteme einzubinden. Standardsätze werden bereits vorgeschlagen.
Usergenerated Content muss eventuell auch internationalisiert werden, bei Kindo weniger Problem, da Familienintern.
Team-Mitglieder übersetzen eventuell besser als Agenturen, da diese besser den Geist der Seite mit Übersetzen können. Agenturen übersetzen weniger frei, finden nicht Entsprechungen, sondern Übersetzungen. Tonalität kann damit eventuell besser herübergebracht werden.
Probleme
- Von Rechts nach Links schreiben
- Skalierungsprobleme
- AGBs? Anwalt in jedem Land? Eventuell ist es kleinen Unternehmen nicht zumutbar, Lokalisierung von AGBs vorzunehmen. Kommt auch auf Markt an, für den die Seite bestimmt ist, Standort der Daten, Sitz der Organisation
- Länderkürzel - 2- oder 3stellig oder 5stellig - Dialekte werden abgebildet?
- Kulturelle Unterschiede bei der Zusammenarbeit
- bei eCommerce Währung, Zahlungsmethoden
- Länder mit mehreren Sprachen
- Benutzereinstellungen im Browser für Sprachen verwenden
- Anzeige von Kalender - welcher Tag ist links?
- Layoutprobleme wegen Wortlänge, mit einplanen beim Layout
- Pluralformen
Barcamp Stuttgart: Webapplikationenn ohne "Offline-Grenze"
Tobias Günther von www.puremedia-online.de spricht über offline-Applikationen im Web-Bereich.
Web-Applikationen können im Vergleich zu Desktop-Applikationen nur online genutzt werden, es sei denn jetzt: Offline-fähige Desktopapplikationen - Offline schließt eine der letzten Lücken zum Desktop!
Komplette statische Seiten können einfach gespeichert werden, Applikationen nicht so einfach, da Datenquelle nötig ist. Sinnvoll für wackelige/instable Verbindungen, aber auch unterwegs, im Flugzeug, beim Kunden… Nicht jede Web-Applikation muss offline-fähig sein. Auch Performance kann ein Kriterium sein.
Beispiele: Google Reader, GearPad, Remember The Milk, Google Docs, Mail Client, CRM, Projektmanagement-Tools, Kalender…
Das Problem ist nicht neu, es gab Dojo Storage, Derby/JavaDB, Zimbra (Derby-based). Heute: Adobe AIR (früher: Apollo), Joyent Slingshot, Apple iPone, Google Gears, Google Gears Mobile.
Adobe AIR: Wirklich eigene offline-Anwendungen in eigener Runtime (muss jeweils installiert werden), damit echte Applikationen ohne Browser. Entwicklung in Flash/Flex oder HTML/Javascript. Vorteile: Zugriff auf Systemresourcen, Taskbar, Autostart…
Joyent Slingshot (Ruby on Rails) - einheitliche und gewohnte Entwicklungsplattform, ansonsten wie Adobe AIR.
Apple iPhone - JavaScript-API (Webkit/HTML5 Spec) - mit Datenbank, Transaktionen…
Weitere/Bald: Mozilla Prism, Microsoft Silverlight (mobile Endgeräte, dann offline-Support), Webkit (Safari) und Firefox 3 eigene Schichten, HTML5 Working Draft WHATWG - “Client-side database storage”
Google Gears
Ist ein Browser-Plugin für Firefox und Internet Explorer, vermutlich bald auch in Opera und Safari. Google Gears ist OpenSource. Motivation von Google Gears ist, dass Google Apps offline nutzbar ist. Ziel: single industry standard, in allen Browsern verfügbar mit einheitlicher API.
Benötigt insgesamt keine echte Installation, kann schnell installiert werden, niedrige Hürde. Alles bleibt bei Google Gears im Browser, alles ist gleich. Auch bei der Entwicklung werden Standardtechnologien eingesetzt, nur JavaScript ist ein wenig erweitert. Schwerpunkt ist die offline-Nutzung, aber keine sonstige Erweiterung der Browser-Funktionalität.
Google Gears besteht aus drei Komponenten, einem LocalServer (eine Art Webserver), eine Datenbank (SQLite) sowie ein Workerpool für Hintergrundprozesse (ein threading-Modell für JavaScript).
Local Server
Liefert definierte Ressourcen aus einem lokalen Cache aus, egal ob offline oder online. Es gibt eine Variante, die automatisch aktualisert, bei einer anderen muss man manuell aktualisieren. Resourcen müssen definiert werden im JSON-Format.
Datenbank
Echte Datenbank mit allen Features, auch mehrere Datenbanken nutzbar. Sandbox-Modell, d.h. man kann nur auf die eigene Datenbank zugreifen. Nichts neues, aber gut.
Worker Pool
Für ressourcenhungrige Prozesse, das Benutzerinterface bleibt benutzbar. Man kann allerdings nicht auf das DOM zugreifen. Einsatzbereich: Synchronisation, auch für online-Applikationen interessant.
Seit 2-3 Monaten auch mobil (Windows Mobile 5&6) nutzbar, exakt gleich wie auf dem Desktop, aber das Gerät hat natürlich Einschränkungen. Mittlerweile gibt es relativ gute Browser auf mobilen Endgeräten, damit können Web-Technologien genutzt werden.
Mobile Applikationen sind oft offline, Performance nicht so groß, große Datenmengen sind schwierig, Gears hilft, um die wiederholte Übertragung großer Datenmengen zu vermeiden.
Zukunft von Google Gears
Desktop-API: Shortcut Icon, fortsetzbare Uploads, GeoLocation API, noch nicht: ImageManipulation API, Audio API, …
Gears? Oder AIR?
Hängt von der Anwendung/Philosophie ab. Adobe AIR eher auf den Desktop konzentriert, erfordert aber eine aufwändige Installation, während Google Gears auf den Browser konzentriert ist und eine einfache Installation bietet. AIR bietet eine sehr reichhaltige Umgebung, ist aber closed source, während Google Gears weniger Funktionen bietet, aber Open Source.
Synchronisation
Standard: Dojo offline gibt es, Synchronisation ist aber unglaublich individuell, keine fertige Strategie, bleibt dem Entwickler überlassen.
Gedanken zu Social Bookmarks
Als im Februar der Social Bookmark Service Taggle.de von Mister Wong übernommen wurde, habe ich mir einige Gedanken darüber gemacht, was mir Social Bookmarks bringen, was ich da will und was ich mit meinen ca. 600 Bookmarks, die ich dort gesammelt hatte, machen will.
Was fand ich bei Taggle.de gut?
Hm, zuerst einmal, wie ich zu Taggle.de gekommen bin - Martin Mündlein hat mich persönlich auf Grund eines Eintrages hier im Blog angeschrieben. Obwohl mich die Qualität des HTML-Codes von Taggle.de eher abgeschreckt hat, habe ich mich daraufhin entschlossen, mich zu registrieren. Vor allem deshalb, weil ich bei Taggle.de sehr interessante Bookmarks gefunden habe. Auf der Startseite waren sehr oft Links zu Web2.0-bezogenen Themen zu finden, sogar das Wort Web2.0, das ich davor noch gar nicht kann, habe ich auf diese Weiße kennen gelernt. Auch auf Anfragen nach Features wurde schnell reagiert, wenn auch nicht alles Versprochene umgesetzt wurde. Auch dass Taggle.de ein Studentenprojekt und nicht primär von einer Firma war, fand ich gut. Klar, technisch war es nicht der Hit, es gab zwei Mal - so weit ich mich erinnern kann - einen längeren Ausfall, die Tag-Vervollständigung war bei meinen vielen Tags nicht mehr wirklich schneller als das Tippen bzw. das Tippen wurde durch sie sehr erschwert, aber dennoch fand ich einfach sozusagen die Community gut.
Was möchte ich für meine Bookmarks in der Zukunft?
Möchte ich überhaupt Social Bookmarks? Also mir ist klar:
- ich möchte auf die Bookmarks von überall aus zugreifen können
- ich möchte meine Bookmarks auch anderen zeigen können
- ich möchte Tags
- der Service sollte einigermaßen gut erreichbar sein (Ausfälle/Geschwindigkeit)
Doch was bringt mir jetzt ein Social Bookmarks-Service gegenüber einer Applikation die auf meinem Webspace läuft (wie z.B. Scuttle)? Hm, ich sehe, wie populär ein Link ist - doch das interessiert mich eigentlich wenig und es hat auch nur bei den großen Seiten wie del.icio.us wirklich ein wenig Relevanz. Aber etwas anderes ist es: ich sehe, welche Tags andere dieser Seite gegeben haben. Und das finde ich echt praktisch, denn es erleichtert einem das Bookmarken ziemlich.
Meine Entscheidung fiel letzten Endes zu Gunsten von del.icio.us und gegen Mister Wong, auch wenn ich mir dort auch erstmal einen Account erstellt und meine Bookmarks importiert habe.
Weshalb del.icio.us? Zum einen ist es dort sehr wahrscheinlich, dass jemand die Seite schon einmal gebookmarkt hat und deshalb bereits schon Tags vorhanden sind. Zum anderen ist ein Ausfall der Seite recht unwahrscheinlich. Außerdem gibt es für del.icio.us für sehr viele Programme (auch Blog-Systeme) Plugins, mit denen man del.icio.us integrieren kann. Scuttle würde diese API, die hier Verwendung findet, auch anbieten, da spielt aber dann die Community die entscheidende Rolle in meiner Entscheidung zu. Was mich letzten Endes überzeugt hat, war der Ruby-wmii Bookmark Manager - ich setzte davor bereits wmii mit der Ruby-Konfiguration ein und hatte das ganze somit schon installiert - und so habe ich nun eine immer (alle 30 Minuten) aktuelle Kopie meiner Bookmarks auf dem PC (d.h. ein aktuelles Backup, ich habe also meine Bookmarks auch zur Verfügung wenn del.icio.us/mein Account mal nicht erreichbar sein sollte) und komme über ein Tastenkürzel sehr schnell an meine sehr schnell und super durchsuchbaren Bookmarks dran - echt klasse! Und zum Hinzufügen klicke ich auf den passenden Button in Firefox und kann die vielen Tags der anderen Benutzer nutzen - auch Klasse! Und ganz am Schluss nun noch ein Link zu meinem Account bei del.icio.us.
My new mail system with fdm and mutt
Since some weeks already I have been using a completely new mail system. I had been using Thunderbird and I had been accessing some accounts with IMAP, some with POP3, some mails had been local, some remote before. And everything was in large files I haven't really trusted. So I decided to set up something new.
Already last year I read about the search for "the" mail client of Michael Klier and therefore it was relatively clear that mutt would be the client of choice. The storage part wasn't that difficult, too. Some mails should be mirrored to a remote IMAP server, but all mails should be in a local maildir.
The interesting question remained: Which software will send the mails with SMTP and which one will fetch and sort them. Well, the first answer is msmtp as it supports multiple SMTP accounts and can be integrated into mutt quite easily. The other answer seemed to be a combination of getmail and procmail - until I had discovered fdm. It supports fetching mails and newposts from various sources (includes IMAP and POP3, but also a local maildir) and delivering mails to many destinations (includes maildir, mbox, IMAP and SMTP). On the way you can filter the mails by a lot of criterias, you can select if the mail shall remain on the server or not and of course you can send it through other programs, too. Additionally it can maintain local lists of mails it already knows so you can skip double mails. The advantage of fdm is that it can e.g. filter old mails, too, it can maintain archives of old mails, …
After reading the documentation I started writing my own configuration file. Although it seems quite complex it's relatively simple if you don't have that many rules and all in all it's quite intuitive. Then the important moment arrived: Fetching mails for the first time. It worked quite well, although it has some flaws I will describe later.
The negative surprise was that authentication with NNTP wasn't supported. Well, I decided to write a mail to the mailing list in order to see what the author thinks about it - and guess, no, you won't guess it - not 24 hours later I had a patch in my inbox that adds the feature I wanted. And it works. That was really cool.
I encountered a couple of bugs with fdm but all obvious problems were solved by the author some hours after reporting them (they were related to NNTP which isn't that well supported…). Apart from some problem with terminating the process I am currently trying to monitor with a more verbose log and the author wants to have a look at fdm currently works, although IMAP with GMail seems to not to work that good… At least if you want to leave all messages on the server you have to mark them as read manually as otherwise fdm will continue downloading them everytime (you can filter them with a seen cache, but it still needs some time…). I've had problems with a large newsgroup and fdm, too. It seemed everytime after looking into the maildir with mutt all messages were downloaded so I ended up with having not only some thousands of messages but almost 20 thousands of messages with every message at least four times or so. That was when I removed that nntp account from my configuration as I haven't read all those messages, anyway.
All in all fdm has really cool features, but seems to be quite unknown (?) and not so good when you have to deal with random (news)servers.
I learned to love my new mail system. There is no longer a Thunderbird window floating around, it's just another window in my screen session. I can now use my favorite editor VIM for composing mails and it seems to me that I no longer constantly look for new mails, too. The next thing is that mutt automatically suggests moving mails out of the inbox into another mailbox specified in the configuration, so I now started to have a clean inbox almost everytime I read through it. Either I delete it (which I do more often now, it's just one single keystroke) or I move it to another folder manually - or it gets into the archive.