Table of Contents
Home
Welcome on my WikiBlog! You can find a mixed collection of German and English content here. This website is always work in progress as there is a lot to do and so little time.
Willkommen auf meinem WikiBlog! Hier gibt es eine Mischung aus deutschen und englischen Inhalten. Meistens habe ich zu viele Ideen und zu wenig Zeit und so ist auch diese Website eine ständige Baustelle.
FuCamp: Blogs vs. Qualitätsjournalismus
Dies ist ein Mitschrieb der kleinen Diskussionssession zum Thema Blogs vs. Qualitätsjournalismus.
In den USA gibt es bereits eine erste (Groß)Stadt ohne Tageszeitung - da die junge Generation die Infos aus dem Internet holt. Primäre Aufgabe einer Tageszeitung ist es allerdings nicht, schnell zu sein, sondern gut zu sein. Tageszeitungen liefern auch Hintergrundinformatione und hat gut ausgebildetete Journalisten, die beide Seiten hören. Twitterer oder Blogger berichten immer bzw. meist einseitig.
Falsche Informationen online werden von den traditionellen Medien übernommen.
Tageszeitungen bieten Dinge, die das Internet nicht bieten kann. Journalisten recherchieren auch länger für ein Thema, Blogger recherchieren selten so gründlich wie Journalisten, z.B. auch in den entsprechenden Ländern. Blogs sind quasi Stammtische im Internet, aber die Printpublikationen springen darauf an.
In Deutschland ist auch eine Konsequenz, dass verschiedene Zeitschriften zu großen Verlagen zusammengeschlossen werden.
Problem ist ebenfalls, dass es den Leuten egal ist, was momentan mit den traditionellen Medien passiert.
Blogs bieten auch Vorteile, sind unabhängig im Gegensatz zu traditionellen Medien, die z.B. von Werbeeinnahmen abhängen und daher schlecht den Werbepartner kritisieren können. Weblogs bieten eine große Meinungsvielfalt, eventuell auch ohne finanzielles Interesse bessere Information?
Problem: Woher kommen die unabhängigen Meinungen? Wohl doch auch von den traditionellen Medien.
Es wird im Bereich des Qualitätsjournalismus immer weniger Geld ausgegeben für Journalisten. Das beschränkt durchaus die Qualität der Inhalte. Die Qualität sinkt ganz von selber durch Anzeigeneinbrüche, Preissteigerung, …
Blogs referrieren gerne auf Medien, Blogs sorgen damit dafür, dass verschiedene Artikel der Presse gelesen werden, beleuchten sie auf andere Weise. Teilweise kommen auch Themen aus den Blogs in die Traditionellen Medien. Blogs zeigen auch, dass man mit wenig Geld einiges erreichen kann.
Bei Blogs werden gute Blogs herausgefiltert.
Bei allen Informationsquellen sind die meisten Informationen irrelevant für die einzelne Person. Blogs erlauben es einem, eine persönliche Zusammenstellung von Informationen zu bekommen. Das Social Network kann als Filter für Informationen dienen, d.h. man liest das, was einem die virtuellen “Freunde” empfehlen.
Blogs haben ihre Daseinsberechtigung im Long Tail, das scheint für uns klar zu sein. Außerdem legen sie teilweise die Themen für die Printmedien fest. In Printmedien sind Information und Meinung (idealerweise) getrennt (in den USA z.B. anders), in Blogs nicht.
Via Twitter/Blogs werden Informationen sehr schnell veröffentlicht, die Frage ist aber, ob die Informationen auch stimmen. Massenmedien schauen auch in die Tiefe, Blogs vermutlich eher weniger. Reine Nachrichten funktionieren eventuell auch ohne Qualitätsjournalismus. Problem ist auch, dass viele auch schnelle Informationen für die richtige Information halten.
Brauchen wir zwar keine traditionellen Medien mehr, aber trotzdem noch Journalisten?
Journalisten machen oft Fehler, wie man merken kann, wenn es um einen selbst schreiben - wie viele Fehler machen sie insgesamt? Bei Bloggern kann man hier einfacher korrigieren. Blogger liefern bei Artikeln einen anderen, persönlicheren Hintergrund in Artikeln.
Mit einem mehr oder weniger offenen Ende schloss diese sehr interessante und spannende Diskussion.
FuCamp: Amazon Web Services
Session von und mit Sven Jansen (@pixeljunkie auf Twitter). Schwerpunkt auf Amazon Elastic Compute Cloud (Amazon EC2) - virtuelle Rechner anmieten, Amazon Simple Storage Service (Amazon S3) - Datenspeicher, u.a. Twitter basiert darauf. Außerdem gibt es SimpleDB - eine einfache Datenbank mit Key-Value-Paaren, aber sehr mächtig. Amazon CloudFront - Frontend für S3 - bringt Daten näher an den Benutzer, legt den S3 Space in die Region, in der die Daten angefragt werden, S3 Spaces werden damit weltweit verteilt. Amazon Simple Queue Service (Amazon SQS), Event-System mit Queues, Elastic MapReduce zum Bearbeiten extrem großer Datenmengen.
Amazon EC2
Basiert auf XEN Virtualisierung, auch CPU-Last und Speicher werden auf mehrere Systeme verteilt, wie genau ist Geheimnis von Amazon. Es gibt verschiedene Linux-Distributionen oder auch Windows. Es gibt verschiedene Ausbaustufen, die auf reale Hardwarekomponenten umgerechnet sind. Die virtuellen Maschinen sind flüchtig, Änderungen an den Daten werden nicht gespeichert, man bootet von einem Image. Der vorhandene Speicherplatz ist für temporäre Daten gedacht, eigentliche Speicherung auf S3. Die Abrechnung erfolgt dabei stundenweise, man kann flexibel wechseln. Innerhalb von 2 Jahren gab es keinen Ausfall, die Ausfallsicherheit ist also recht hoch. Man sollte die Dienste so bauen, dass andere Server schnell dafür einspringen können.
Es gibt als Ergänzung auch Elastic Block Storage dazu für nicht-flüchtige Speicherung von Daten. Die Server stehen in den USA und Irland. Es gibt feste IPs, die nicht an einen einzigen Server gebunden sind. Cloudwatch ist ein Dienst, um die verschiedenen Daten zu überwachen, bietet API an.
Autoscaling - automatisch Instanzen starten/beenden wenn sich der Bedarf ändert. Seit kurzem auch Elastic Load Balancing, Routing auf mehrere Instanzen. Snapshots der Instanzen können auf S3 gespeichert weren, z.B. um Updates am Betriebssystem selbst zu machen, geht sehr schnell. Es gibt einen Marketplace mit kostenlosen oder auch kostenpflichtigen fertigen Images.
Die API ist programmiersprachenunabhängig.
Amazon S3
“Eimer” benennen, Daten reinladen (REST/SOAP API). Verfügbarkeit durch HTTP Download, aber auch BitTorrent, API. Unbegrenzter Speicherplatz, aber max. Dateigröße 5 GB. Standorte USA oder Irland. Es gibt auch Rechtemanagement, Zugriff kann beschränkt werden. Das ganze ist auf mehrere Server verteilt und kann mit Cloudfront auf eigene Domain und Edge Server geleitetet werden. Es gibt als Minimum 100 MBit Anbindung, Traffic kostet.
Die Bezahlung erfolgt in beiden Fällen ausschließlich über Kreditkarte.
FuCamp: Laptops in Vorlesungen - Fluch oder Segen?
In Furtwangen wurde Kritik an den Notebooks in Vorlesungen von Seiten der Professoren geäußert. Anwesend auch ein Professor der Hochschule.
Folgend der Mitschrieb einiger Aussagen/Lösungsideen, …
Notebooks können gut genutzt werden für Protokolle, Recherche, … Studierende finden es unverschämt, dass ihnen während der Vorlesung der Kontakt nach außen verboten wird vs. der Professor, der versucht, etwas mitzuteilen und die Studierenden lenken sich ab.
Heute existiert eine andere Kommunikationskultur als früher - wie unterscheiden sie sich? Müsste man Laptop-Nutzung verbieten oder wie bekommt man sie sonst in den Griff? In Dänemark wurden Laptops teilweise sehr integriert, dass Ablenkungen von Studierendenseite selbst als störend empfunden wurde. Zum Beispiel durch Skripte ergänzen oder Studierende müssen während der Vorlesung ein Programm erstellen.
Digitale Mitschriebe bieten große Vorteile (können z.B. an nicht anwesende Studierende weitergegeben werden). Langweilige/schlechte Vorlesung - gehen vs. ablenken und trotzdem noch ein wenig aufpassen.
In manchen Vorlesungen ist es offensichtlich, dass Laptops nicht zu studienzwecken einzusetzen. Teilweise gibt es auch Pflichtveranstaltungen, wo man hingehen muss. Außerdem sind Studierende teilweise gestresst/haben nicht so viel Zeit und erledigen andere kleine Aufgaben wie E-Mails schreiben.
Professoren empfinden es als sehr wichtig, dass sie die ungeteilte Aufmerksamkeit bekommen und ihre Selektionsfunktion ausüben können, da sie eine Fachsicht haben und die Studierenden selbst nicht unbedingt beurteilen können, ob die Inhalte interessant sind.
Problem bei Pflichtvorlesungen, dass Studierende da sind, die ohne Anwesenheitspflicht nicht da wären.
Es gibt Vorlesungen, in denen Laptops nicht sinnvoll und es gibt andere, in denen man mit dem Laptop z.B. Aufgaben zum aktuell behandelten Stoff lösen kann.
Laptops in Vorlesungen lenken auch andere Studierende, insbesondere die, die dahinter sitzen, teilweise auch akustische Störung.
In manchen Vorlesungen sind Laptops zur Recherche sehr sinnvoll.
Sensibilisierung für das Thema wird eher als Lösung gesehen als ein generelles Verbot, da damit auch sinnvolle Einsatzgebiete verboten werden. Es ist auch eine Frage der Grundeinstellung. Idee einer Selbstverpflichtung - aber es gibt evtl. immer schwarze Schafe. Soziale Bindung/Kontrolle ist in Kleingruppen möglich.
Durch handschriftliche Mitschriebe wird man gezwungen, die Vorlesung wirklich nachzuarbeiten. Am Computer dagegen kann man dagegen übersichtlicher Mitschreiben und auch die mitgeschriebenen Inhalte durchsuchen.
Problem ist, dass die Diskussion eigentlich alle erreichen müsste, und nicht nur diejenigen, die sowieso für das Thema sensibilisiert sind.
Lösungsvorschläge:
- Wir hoffen, dass sich die Leute ändern
- “Holzhammer-Methode” - Professoren sagen es am Anfang der Vorlesung
- Graswurzelbewegung - aus der Menge heraus wird Druck aufgebaut
Bericht auch, dass Ermahnen anderer nicht unbedingt hilft.
Eventuell sollte es auch einen Grundsatz/ein Leitbild geben. Aufruf an die Studierenden, hierfür Vorschläge einzureichen.
FuCamp: Blinde am PC
Session mit Markus Heurung, @muhh, markusheurung.de, Lehrer am Berufsförderungswerk Würzberg (bieten Umschulungen an), bildet in IT-Berufen auf, in diesem Fall für blinde und sehbehinderte Menschen zur Wiedereingliederung. Blindenschrift lernen, leben als Blinder.
Hilfsmittel Nr. 1 sind Screenreader, der den Bildschirminhalt ausliest und für Blinde zugänglich macht. Die Darstellung kann über eine Braille-Zeile oder Sprachausgabe erfolgen. Der Screenreader bekommt seine Informationen von einfachen Programmierschnittstellen bis hin zur Grafikkarte, wo die Cursorposition erfragt wird. Einer der verbreitetsten ist Jaws, auch verbreitet Virgo/Cobra, Window Eyes und die OpenSource Software NVDA. Von allen gibt es Demo-Versionen, die meist auf 40 Minuten pro Boot… Ubuntu kann man auch blind installieren, bei Windows geht das nicht, bei Mac OS ist auch einiges vorhanden.
In den USA benutzen die meisten einen Screenreader mit Sprachausgabe aus Kostengründen, in Deutschland sind eher die Braillezeilen gefragt. Viele arbeiten auch kombiniert mit beidem.
Screenreader sind extrem konfigurierbar, Sprachgeschwindigkeit einstellbar, “Bubbles” aus der Statuszeile werden vorgelesen. Es gibt unterschiedliche Stimmen, auch unterschiedliche Stimmen für verschiedene Funktionen.
Das Wichtigste für Blinde bei Programmen und auch Websites sind Shortcuts, Grafiksymbole beschriften (z.B. alt-Attribute bei Bildern auf Websites). Es muss des Weiteren alles mit der Tastatur erreichbar sein. Bei Websites können Screenreader z.B. auch Übersichten mit allen Überschriften oder Links anzeigen.
FuCamp: La Blogosphère en France
Session mit Dr. Heiner Wittmann von der Ernst Klett AG, ist dort verantwortlich für Web 2.0 bei Klett.
In Frankreich vs. Deutschland 9 vs. 1 Millionen Blogs, in Frankreich viel mehr Blogs, da aktivere Blog-Platformen. Politiker bloggen teilweise selbst, teilweise lassen sie auch bloggen (auch gemischt in einem Blog). Mind. 80 verschiedene franz. Abgeordnete haben Blogs. In Deutschland gibt es das weniger, da ca. die Hälfte der Abgeordneten mit Listen gewählt werden, französische Politiker sind eher gezwungen, mit ihren Wählern im Kontakt zu bleiben. In Frankreich können einzelne Politiker direkt abgewählt werden, in Deutschland quasi nicht möglich wegen den Listen.
In Frankreich wird oft über die Arbeit an Berichte und Projekten gebloggt, eine Offenheit, die wir in Deutschland oft noch nicht haben.
Bei französischen Medien gibt es teilweise Blogs der Zuschauer, bei Le Monde sind teilweise bekannte Blogs in Frankreich gehostet.
Es gibt Theorien, dass beim Referendum zur EU-Verfassung die Blogs auch mit entschieden haben.
Die Blogs vernetzen sich oft mit anderen lokalen Blogs.
Mit Sicherheit stecken gerade bei Politikern wie Sarkozy PR-Berater dahinter, die normalen Abgeordneten machen das aber wohl doch selbst.
Mehr Infos, Links etc. auf http://romanistik.info/blogs.html
FuCamp: Freie Suche
Präsentiert von zwei Informatikstudenten (Uni Karlsruhe):
- Florian Richter
- Michael Hamann
Motivation
- Suche ist eine der wichtigsten Dinge im Web überhaupt
- Die Websuche ist momentan in der Hand weniger großes Konzerne
- Zensur, Kontrolle - wie vertrauenswürdig sind derartig riesige Privatunternehmern
YaCy
- P2P Suchmaschine - verteilte Indexierung des Webs
- 2003 Gegründet
- momentan ca. 7 aktive Entwickler
- momentan ca. 70 Aktive Teilnehmer im P2P Netz
P2P
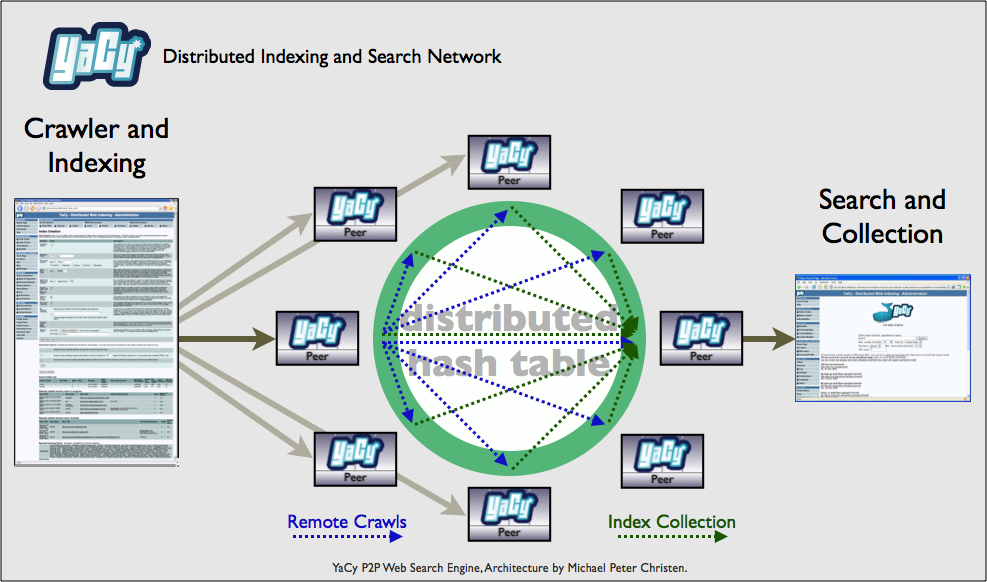
Zensur
- Jeder Peer kann Blacklists anlegen, diese können ausgetauscht werden
- Gedacht, um z.B. Werbung, Linkfarmen, etc. auszuschließen, teilweise auch eBay, Amazon etc.
- Problem: Bei Verteilung wird der Index teilweise auch auf den anderen Peers nochmal nach dortigen Blacklists zensiert
- Zensur vs. Spam/unerwünschte Inhalte?
Weitere Einsatzzwecke
- Firmen Intranets
- Themensuchmaschinen
- ScienceNet am KIT
Ersatz für Google?
- Bereits brauchbare Ergebnisse
- Index umfasst natürlich nicht alles.
- Lösung: Metasuchmaschine - Paxle?
Auch online:
FuCamp: Distributed Social Networks
Session mit Mario Volke, studiert Informatik und hat sich von der semantischen Schiene her mit Distributed Social Networks beschäftigt.
Es geht darum, keine geschlossene Plattformen zu haben ohne Kontrolle über die eigenen Daten. Die Idee ist, plattformübergreifend Freunde zu haben und vielleicht sogar die Daten selbst zu speichern. Hierzu sind offene Schnittstellen nötig.
Was gibt es?
Google OpenSocial: Wollen bestehende Netzwerke öffnen mit Hilfe von APIs für Userdaten, Freunde, Aktivitäten. Alles ist sehr unspezifisch. Nicht möglich sind aber plattformübergreifende Freundschaften, die Daten liegen nach wie vor bei den geschlossenen Plattformen, keine wirkliche Dezentralisierung.
NoseRub ist ein OpenSource-Projekt, eine Plattform, die man selbst installieren kann. NoseRub spezifiziert ein Protokoll, mit offenen Technologien mit OpenID, RSS, FOAF. Man kann Streams aggregieren, Livestreaming (wie z.B. FriendFeed). Man hat eine URL, die die eigene ID darstellt. Die Profile werden über FOAF synchronisiert.
HelloWorld - www.helloworld-network.org, aus Diplomarbeit entstanden, noch nicht live, SourCode in ein paar Monaten… Authentifizierung mit ähnlichem Protokoll wie OpenID mit Public Key Verfahren. Dezentralität: Profile, Unterprofile, freie Wahl des Speicherortes dieser Profile. Spezielles Protokoll zur Verbindung der verschiedenen HelloWorld-Server existiert. Sicherheit mit Hilfe von Verschlüsselung und Signaturen. Die Kommunikation soll über E-Mail oder Peer-to-peer (z.B. Freenet), ist aber noch nicht implementiert. Es gibt von der RE:Publica eine Aufzeichnung der dortigen Live-Demo.
Ein Projekt von Mario selbst ist origo. Eine Mischung aus Serverapplikation mit PHP mit einem Datenspeicher und einem Flex Client, über das man das Profil (FOAF) editieren kann und das Netzwerk erkunden kann. Der Server kümmert sich auch um die Publizierung der Profile. Es gibt URLs für die Profile, können auch Weiterleitungen sein. Problem ist, dass FOAF noch etwas beschränkt ist. Der Client enthält einen Browser für das soziale Netzwerk, auch nach spezifischen Beziehungen. Beziehungen wie child of/parent of werden auch erkannt. Auf http://code.google.com/p/origo/ gibt es den Code und Links zu demos. Auch externe Profile können mit angegeben werden. Alles ist noch experimentell, auch die Performance ist noch problematisch, da die Daten wirklich dezentral auf anderen Servern gespeichert sind und erst angefragt werden müssen. Es werden ausschließlich standardisierte Protokolle verwendet, Dinge wie andere Personen über neue Freundschaften informieren funktionieren noch nicht.
Was wollen wir?
Kontrolle über die eigenen, persönlichen Daten.
Frage: Wie werden die Profildaten wieder zurück in anderen Profile synchronisiert. Plattformen sollten die Daten nur aus FOAF-Profilen nur cachen, die anderen müssen diese Daten ab und zu synchronisieren. Die eigenen Profile enthalten die Daten, die einzelnen Plattformen sind nur Clients. Problem, dass die Plattformen die Caches richtig verwalten müssen/garantieren müssen, dass die Daten auch wirklich wieder gelöscht werden, wenn der Benutzer es will. Problem, dass einmal veröffentlichte Daten schlecht zurückgenommen werden kann.
Frage auch nach einem Geschäftsmodell, einem Markt, … Das Daten/Profil erstellen fällt als Geschäftsmodell eventuell weg oder wird es hier wieder zentrale Anbieter geben? Vergleich mit E-Mails, wo auch Geld mit verdient wird. Die Frage ist, ob XMPP genutzt werden könnte, für die Kommunikation. Problem auch der dezentralen Adressierung, ob E-Mail-Adressformat oder URI, …
Das Problem ist auch, dass der Ottonormaluser nicht das Problem sieht/den Mehrwert erkennt. Auch die Akzeptanz von Kryptographie ist nicht unbedingt gegeben (siehe E-Mail).
Interessante Diskussion zum Thema Zentrale Identität vs. verteilte Daten usw.. Problem dass man die eigenen Daten an eine private Firma überträgt.
Es ist klar, dass die zentralen Plattformen, die die Massen haben, kaum Interesse haben an dezentralen Netzwerken, aber sie könnten dazu gezwungen werden (siehe AOL…). Selbes Problem existiert auch bei Instant Messaging, Google stellt sich hier hinter Jabber, aber Jabber setzt sich bis jetzt immer noch nicht durch…
FuCamp - E-Learning 2.0
Session mit Katrin Mathis, sie schreibt E-Learning Bachelor Thesis - E-Learning in sozialen Netzwerken, wie kann man es vermarkten, …
Warum brauchen wir E-Learning 2.0? Wissen kurzlebig, neue Berufsbilder, hohe Qualifikation gefordert, Arbeitsbedingungen verändert, arbeiten von zu hause aus. Früher einmal gelernt, heute lebenslanges lernen.
Die NetGeneration der digital natives (1977-1997) sind mit dem Internet verbunden. Machen viele Dinge gleichzeitig, Fernsehen ist nur im Hintergrund, da sie eher aktiv. Auch kritisiert wird die kurze Aufmerksamkeitsspanne, es gibt aber auch Wissenschaftler, die das positiver bewerten, da es zu unserer modernen Kommunikation mit SMS etc. passt. Auch eine globale Generation, ähnlicher Lebensstil auf der ganzen Welt. Sie will Entscheidungsfreiheit, keine langfristige Arbeit, alles anpassen, selbst zusammenstellen, … Zusammenarbeit mit anderen z.B. über Instant Messaging spielt eine wichtige Rolle. Sie forschen nach, informieren sich z.B. über Produkte aus dem Supermarkt, dank neuer Datenlage, geben diese Informationen/Kaufentscheidungen auch weiter. Unterhaltung und innovative Arbeitgeber sind wichtig. Heute sind auch die nötigen Werkzeuge vorhanden (siehe Wahl von Obama). Man muss auch sehen, dass die Net Generation nicht die gesamte Generation umfasst. Irgendwie muss ich sagen, das Gefühl habe, dass die net generation nur einen eher kleinen Teil umfasst…
Kontakte als Wissensquellen sind heute wichtig, das wirklich wichtige heute ist Methodenwissen, eher Konzepte als das konkrete Wissen lernen. Auch die Trennung von Job und Privatleben wird aufgehoben. Im Internet gibt es keine Beschränkungen für die Spezialisierung des Wissen (z.B. exotische Sprachen). Der Lehrerende ist weniger ein Lehrer als mehr ein Coach, der z.B. filtert. Formelles vs. informelles lernen (z.B. von Kollegen, in Gesprächen, …). Auch Kinder fangen schon mit Computern, Lego, … an. Formelles lernen macht einen Großteil der Ausgaben aus, informelles lernen dagegen liefert einen Großteil des Wissens. Informelles lernen kann man z.B. durch gemütliche Ecken zum Zusammensitzen fördern, mit z.B. Flipcharts etc. ausgestattet. Diskussion, ob wir gerade formal oder informell lernen, scheint eher ein Zwischending zu sein. Wir kommen nicht mit einem bestimmten Ziel hierher, nicht, um z.B. einen Schein zu bekommen. Es gibt Unterschiede zwischen Wissensquellen lesen und lernen, lernen, ist, wenn man das wissen auch nutzen kann. Das meiste informelle Lernen passiert zufällig, aber ist Wissensmanagement lernen? Nicht jede Kommunikation ist lernen, aber man muss kommunizieren, um zu lernen. Informelles lernen ist schwer messbar, schwer kontrollierbar, kommt beim Kaffeetrinken wirklich etwas zustande.
Informelles lernen ist für Grundlagen weniger geeignet, eher für erfahrererne Lernen, hier aber durchaus effektiver.
Also Technologien gibt es Personal-Learning Environments zum selbst zusammenstellen aus Widgets, z.B. Vokabeln, Tageszeitung, …, kleine Einheiten, Stichwort Microlearning. Auch im Bereich Open Source/Content gibt es einiges. Mobile Learning gibt es bis jetzt eher wenig, wird aber zunehmend. Game-based Learning, gerade für Kinder spielerisches Lernen. VOIP Technologien, z.B. bei Sprachenlernen mit Muttersprachlern unterhalten. Software as a Service ist eine weitere Entwicklung, die Software wird im Internet angeboten.
Tools die eingesetzt werden sind Blogs, Wikis, Podcasts, File sharing, RSS, Tagging zum Filtern, Social Bookmarking ebenfalls zum Filtern von Informationen, Social Networking zur Beantwortung von Fragen. Chat und VOIP zur Kommunikation werden ebenfalls eingesetzt.
Edmodo ist eigentlich eine reine Microblogging-Seite, aber man kann auch Termine etc. verschicken. Gedacht für Grund- und Weiterführende Schule. Katrin hat eine FaceBook-Applikation apps.facebook.com/thesisapp. Mit angebundenem Learning Managements System, man kann seine Skills einschätzen, man kann Gruppen bilden, es gibt ein Diskussionsforum, Anbindung an Delicious, Twitter, RSS-Feeds, Aufgabenverwaltung. Es gibt nicht eine Plattform, sondern viele, kein klares Ziel, nur auf Anfrage, problembasiert, geht von den Benutzern selbst aus, mit Echtzeitkommunikation.
Herausforderungen sind Datenschutz, was machen die Firmen mit den Daten? Wie findet man sinnvolle Lernmaßnahmen? Es gibt keine Standards, … Wie kann man informelles Lernen formalisieren?
Zukunft? Semantic Web - intelligent agents, die Hilfestellungen leisten beim finden und filtern geeigneter Informationen, Ubiquitous computing - mobile learning, Internet überall, Virtuelle Welten/3D-Technik, einfacherere Kommunikation, …
Wie setzt man die Tools richtig ein, dies ist die eigentliche Herausforderung beim E-Learning, damit die Lernplattformen wirklich genutzt werden.